Pipeline
Generating novel views for general scenes or objects from only a single image is inherently challenging due to the difficulty of inferring both geometry and missing texture. We therefore tackle this challenge by cultivating the dark knowledge of pretrained 2D diffusion models.
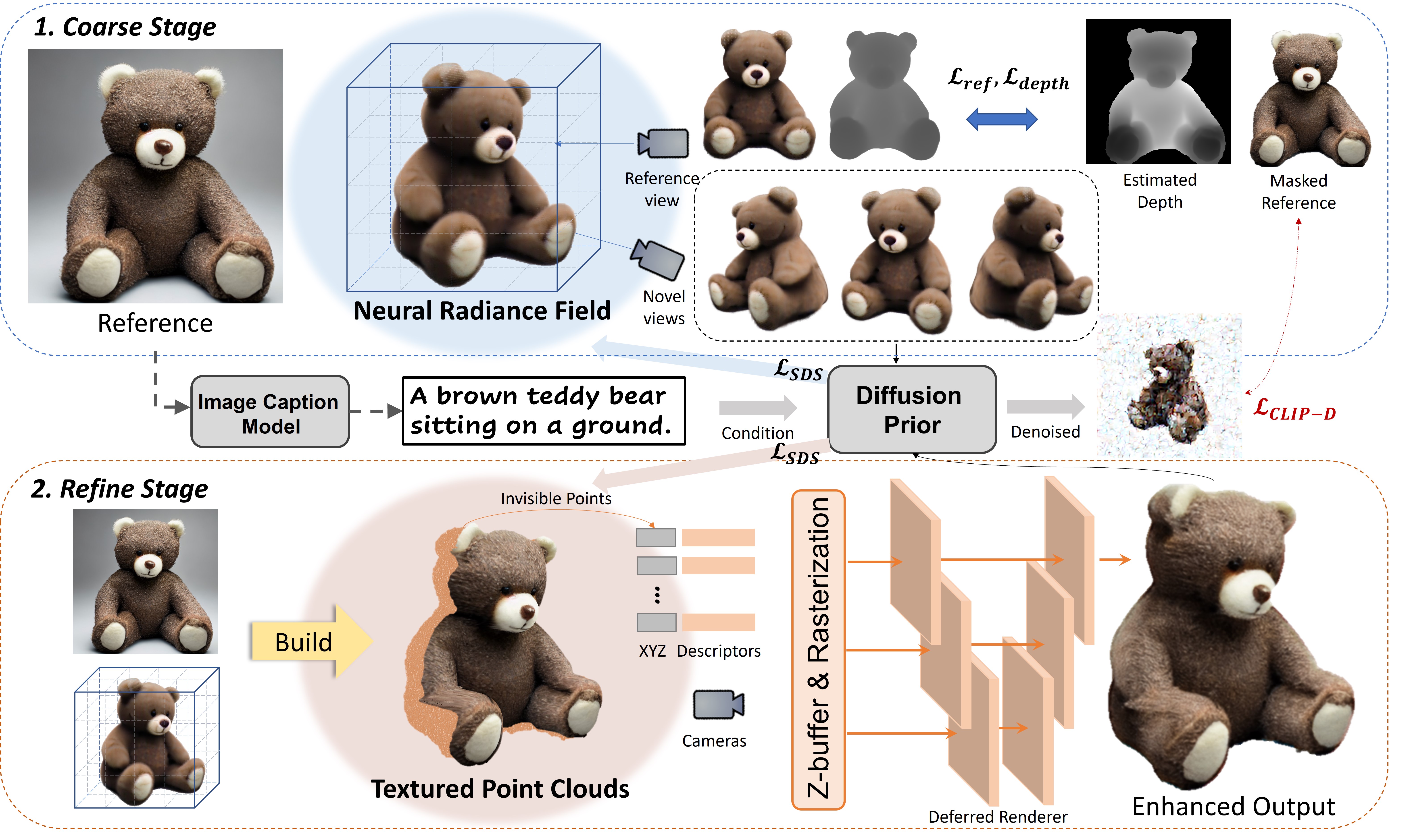
Given an input image, we first hallucinate its underlying 3D representation, neural radiance field (NeRF), whose rendering appears as a plausible sample to a pretrained denoising diffusion model, and we constrain this optimization process with the texture and depth supervision at the reference view. To further improve the rendering realism, we keep the learned geometry and enhance the textures with the reference image. As such, in the second stage, we lift the input image to textured point clouds and focus on refining the color of the points occluded in the reference view. We leverage prior knowledge of the text-to-image generative model and the text-image contrastive model for both stages. In this way, we achieve a faithful 3D representation of the input image with restored high-fidelity texture and geometry.